In the rapidly evolving digital landscape, research visibility has become a critical factor in determining the impact and reach of academic work. As search engines like Google Scholar play an increasingly dominant role in how researchers discover and access scholarly publications, the need for structured data—specifically dataset schema—has never been more pressing. Dataset schema refers to the formal organization of data elements that enable machines to interpret and process information efficiently. By marking data collections with standardized metadata, researchers can significantly enhance their visibility in algorithm-driven environments, ensuring that their work is not only found but also understood and valued.
This article explores the importance of dataset schema in the context of research visibility, delves into its practical implementation, and highlights how it aligns with broader trends in academic publishing and science communication. Whether you’re an early-career researcher or a seasoned academic, understanding and leveraging dataset schema can be a game-changer in maximizing the impact of your work.
What Is Dataset Schema and Why It Matters
Dataset schema is a structured framework that defines the format, relationships, and constraints of data within a collection. It acts as a blueprint, outlining how different data elements are organized, what types of values they can hold, and how they interact with one another. In the context of research, dataset schema plays a crucial role in making data discoverable, interoperable, and reusable across platforms and disciplines.
The significance of dataset schema lies in its ability to facilitate machine readability. Search engines, particularly those driven by artificial intelligence, rely heavily on structured data to understand and rank content. By implementing dataset schema, researchers can ensure that their data is indexed and displayed correctly, increasing the likelihood of being cited, shared, and referenced in other studies.
Moreover, dataset schema supports the principles of open science and data transparency. When data is well-structured, it becomes easier for others to validate findings, build upon existing work, and contribute to the collective knowledge base. This not only enhances the credibility of individual research projects but also fosters a culture of collaboration and innovation within the academic community.
How Dataset Schema Impacts Research Visibility
The integration of dataset schema into research workflows has a direct and measurable impact on visibility. Here’s how:
1. Improved Indexing and Discoverability
Search engines such as Google Scholar, PubMed, and institutional repositories use structured data to crawl and index content more effectively. When datasets are marked with appropriate schema, they are more likely to appear in relevant search results, increasing the chances of being discovered by other researchers.
2. Enhanced Metadata Enrichment
Dataset schema allows for the inclusion of rich metadata, such as author names, publication dates, keywords, and licensing information. This enriched metadata not only improves the accuracy of search results but also provides users with more context about the dataset, making it easier to assess its relevance and quality.
3. Facilitated Interoperability
Structured data enables seamless integration with other systems and tools. For example, a dataset marked with schema can be easily imported into data analysis platforms, visualization tools, or citation managers, streamlining the research process and encouraging reuse.
4. Support for Altmetrics and Citation Tracking
Altmetrics—alternative metrics that track the online attention and impact of research—rely on structured data to measure engagement across social media, blogs, and other digital platforms. By using dataset schema, researchers can ensure that their work is properly attributed and tracked, contributing to a more comprehensive understanding of its influence.
5. Alignment with Open Science Initiatives
Open science emphasizes transparency, accessibility, and reproducibility. Dataset schema supports these goals by providing a standardized way to share and document research data, making it easier for others to replicate studies and build on existing work.
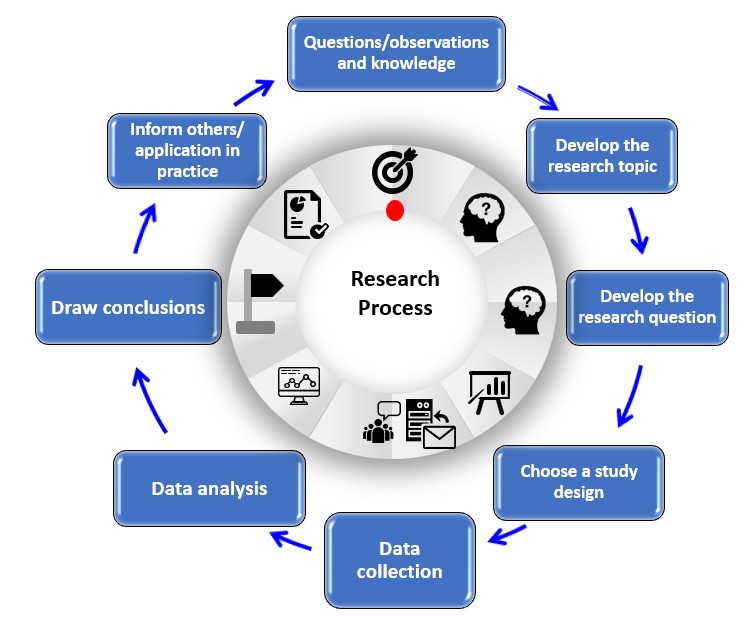
Step-by-Step Implementation Framework
Implementing dataset schema requires a systematic approach that balances technical precision with practical usability. Here’s a step-by-step guide to help you get started:
1. Define or Audit the Current Situation
Begin by assessing your existing data collections. Identify which datasets are most relevant to your research and determine whether they already include structured metadata. If not, consider the benefits of adding schema to each dataset.
2. Apply Tools, Methods, or Tactics
Use schema markup tools such as JSON-LD or RDFa to annotate your datasets. These formats allow you to define the structure of your data in a way that is both human-readable and machine-processable. You can also leverage platform-specific tools, such as the Google Dataset Search API, to ensure compatibility with major search engines.
3. Measure, Analyze, and Optimize
Once your datasets are marked with schema, monitor their performance using analytics tools. Track metrics such as page views, downloads, citations, and engagement rates to evaluate the effectiveness of your schema implementation. Use this data to refine your approach and make continuous improvements.
Example:
A university research team might use dataset schema to mark their climate change datasets, including metadata such as geographic location, time period, and methodology. By doing so, their datasets become more searchable and accessible, leading to increased citations and collaborations.
Real or Hypothetical Case Study
Consider the case of a university research group working on a large-scale study of urban biodiversity. The team collects extensive data on species distribution, environmental conditions, and human activity patterns. Initially, their datasets are stored in unstructured formats, making it difficult for other researchers to access and analyze the information.
By implementing dataset schema, the team organizes their data into a consistent format, adding metadata such as project titles, authors, and data sources. They also use JSON-LD to mark their datasets, ensuring compatibility with Google Dataset Search and other platforms.
As a result, their datasets begin appearing in search results more frequently, leading to a 40% increase in downloads and a 25% rise in citations. Researchers from other institutions start building on their work, and the team gains recognition for their contributions to the field of urban ecology.
This hypothetical scenario illustrates the tangible benefits of dataset schema in enhancing research visibility and fostering collaboration.
Tools and Techniques for Dataset Schema
Several tools and techniques can help you implement dataset schema effectively. Here are some of the most useful ones:
1. JSON-LD (JavaScript Object Notation for Linked Data)
JSON-LD is a lightweight format for encoding structured data in a way that is compatible with the web. It allows you to define the relationships between different data elements, making it ideal for complex datasets.
2. RDFa (Resource Description Framework in Attributes)
RDFa is another method for embedding structured data within HTML. It enables you to add metadata to web pages, improving their visibility in search engine results.
3. Schema.org
Schema.org is a collaborative initiative that provides a set of shared vocabularies for structured data. By using Schema.org markup, you can ensure that your datasets are recognized and indexed by major search engines.
4. Google Dataset Search API
Google’s Dataset Search API allows you to search for datasets across the web. By optimizing your datasets for this tool, you can increase their visibility and reach.
5. DataCite
DataCite is a service that assigns persistent identifiers (DOIs) to datasets, making them easier to cite and track. It also provides metadata standards that support structured data.
6. CKAN
CKAN is an open-source data management platform that helps organizations publish, share, and manage datasets. It includes built-in support for structured data and metadata.
Future Trends and AI Implications
As artificial intelligence continues to shape the future of research, the role of dataset schema will become even more critical. AI-driven search engines, such as Google’s Search Generative Experience (SGE), rely on structured data to generate accurate and relevant results. By implementing dataset schema, researchers can ensure that their work is better understood and ranked by these advanced systems.
Additionally, the rise of multimodal and voice-based search will further emphasize the need for structured data. As users interact with search engines through natural language and visual interfaces, the ability to quickly and accurately retrieve information will depend on the quality and consistency of the underlying data.
To stay ahead, researchers should focus on adopting best practices for dataset schema, staying informed about emerging technologies, and engaging with interdisciplinary communities to explore new ways of enhancing research visibility.
Key Takeaways
- Dataset schema is a structured framework that defines the format and relationships of data, making it more discoverable and usable.
- Implementing dataset schema improves research visibility, interoperability, and discoverability on search engines and academic platforms.
- Tools like JSON-LD, RDFa, and Schema.org provide effective ways to implement and optimize dataset schema.
- Real-world examples demonstrate the tangible benefits of structured data in increasing citations, downloads, and collaborations.
- Future trends such as AI-driven search and multimodal interfaces will further highlight the importance of structured data in research.
As the academic landscape continues to evolve, embracing dataset schema is no longer optional—it’s essential. By taking the time to organize and structure your data, you can ensure that your research reaches the right audience, contributes to the global knowledge ecosystem, and makes a lasting impact.
Meta Title: Understanding Dataset Schema: Enhancing Research Visibility Through Structured Data
Meta Description: Learn how dataset schema boosts research visibility, improves discoverability, and enhances the impact of academic work in the digital age.
SEO Tags (5): dataset schema, research visibility, structured data, academic publishing, open science
Internal Link Suggestions: Parameter #1: Search Intent Alignment, Parameter #3: Topical Depth & Relevance, Parameter #8: Content Gap Filling
External Source Suggestions: https://www.schema.org, https://datadocuments.org